|
Note
|
This document is under active development
If you find errors or omissions in this document, please don’t hesitate to submit an issue or open a pull request with a fix. New contributors are always welcome! |
Mandrel is a distributed mining engine built for the cloud. Features include:
-
Distributed and Highly Available mining Engine.
-
Powerful and customizable
-
HTTP RESTful API
-
Open Source under the Apache License, version 2 ("ALv2")
Introduction
What is Mandrel?
Mandrel is designed as a whole product, with the idea of bringing a complete mining engine solution that runs out of the box.
The Big Picture
Mandrel is designed for performance and scalability. Daily battle-tested on small and on medium-sized cluster (~30 nodes), Mandrel can scale on cloud-sized cluster without any effort.
Mandrel is NOT:
-
a search engine (but you can use Elasticsearch or Solr -or whatever you want- as output)
-
a NoSQL database
-
a SDK
What for?
Mandrel can be used to build various mining jobs:
-
Web crawlers: make the web your in-house database by turning web pages into data
-
SEO analytics: test web pages and links for valid syntax and structure, find broken links and 404 pages
-
Monitor sites to see when their structure or contents change
-
Build a special-purpose search index, intranet/extranet indexation…
-
Maintain mirror sites for popular Web sites
-
Search for copyright infringements: find duplicate of content
Compared to…
Nutch
Big, big Java project. Open-source. Built for crawling all the web and can be distributed on several machines, such as on AWS or any other cloud provider, as well as crawling a specific targeted group of websites, every x days or hours. The architecture is pretty heavy and has lots of dependencies (ant, gora, hbase, hadoop, etc.). Very powerful and manages scheduling, domain restriction, politeness, etc. Can be run in standalone without Hadoop. Very polite and makes sure that there is only one query per host running at the same time, to avoid being blacklisted. Run from the command.
In distributed mode, Nutch need a full Hadoop stack (…) and use (veryyyy) long-running MapReduce in order to sort and crawl URL.
Last version is Nutch 2.x, which is a huge rewrite almost from scratch and therefore not so close to 1.x. However, Nutch 2.x is slower and has less features than Nutch 1.x.
In addition to the crawler feature, Nutch is also a search engine and use Lucène to index documents.
Heristrix
Heritrix is the Internet Archive’s open-source, extensible, web-scale, archival-quality web crawler project. Have Web Control management interface. A powerful job definition, but based on Spring beans definition. Not designed to be scalable.
Last version is 3.2.0 (Jan 2014).
Scrapy
Open-source Python project, best suited for scraping focused websites. Light and easy to use,. Useful when building a handmade parser on a known website in order to extract precise informations.
Not distributed by default, so not a right tool for a huge amount of websites or big websites. Some initiatives aimed to add cluster features (Distributed Frontera and Scrapy Cluster) to Scrapy but are difficult to deploy since they are based on Kafka and/or HBase and need an Hadoop cluster. Politness is respected, but only one process can download on one host at a time.
Internals
Mandrel uses Atomix, Thrift, Netty, Undertow and Spring. It can be connected to:
-
Mongo
-
Elasticsearch
-
Kafka
-
Cassandra
-
Hbase + HDFS
-
"Insert your favorite database here"
Quick Start
Getting Started
System Requirements
Mandrel works on Linux, Mac and Windows. All you need is Java 8+ and a running instance of Mongo 3.0+.
|
Tip
|
If you want to quickly setup a running Mongo instance, use Docker: docker run -p 27017:27017 --name mongo-mandrel -d mongo |
Setup
Installation
With the archive
This is the easiest method, you can download the latest version here: https://dl.bintray.com/treydone/generic/
Just unzip the archive and you are done.
With RPMs
Using yum
-
Copy this text into a 'mandrel.repo' file on your Linux machine:
#For Mandrel
[mandrel]
name=mandrel
baseurl=https://dl.bintray.com/treydone/rpm
gpgcheck=0
enabled=1OR
-
Run the following to get a generated .repo file:
$ wget https://bintray.com/treydone/rpm/rpm -O mandrel.repo
-
Move the repo file to /etc/yum.repos.d/
$ sudo mv mandrel.repo /etc/yum.repos.d/
-
Run the installation command
- RHEL and Fedora 21 or earlier
$ sudo yum install mandrel- Fedora 22 or later
$ sudo dnf install mandrel
By downloading
You can directly download the rpm by using:
$ curl -L "https://dl.bintray.com/treydone/rpm/mandrel-XXX.noarch.rpm" -o mandrel.noarch.rpm
And install it via the rpm command
$ rpm -Ivh mandrel.noarch.rpm
With DEBs
Using apt-get
To install Mandrel on Debian Sid or Ubuntu Saucy or greater:
-
Using the command line, add the following to your /etc/apt/sources.list system config file:
$ echo "deb https://dl.bintray.com/treydone/deb {distribution} {components}" | sudo tee -a /etc/apt/sources.list
OR
-
Add the repository URLs using the "Software Sources" admin UI:
deb https://dl.bintray.com/treydone/deb {distribution} {components} -
In a terminal, type the apt-get command
$ sudo apt-get install mandrel
By downloading
You can directly download the deb by using:
$ curl -L "https://dl.bintray.com/treydone/deb/mandrel-XXX.deb" -o mandrel.deb $ dpkg -i mandrel.deb
From the sources
Mandrel uses Maven 3.3+ for its build system. Simply run:
mvn clean install -DskipTests
cd standalone
mvn spring-boot:run -DskipTestsWith Docker
Be sure to have Docker on your machine. If not:
$ curl -fsSL https://get.docker.com/ | sh
Coming soon…
On Windows
Coming soon…
Build a release
A release can be built with the maven-release-plugin and pushing the new tag. Travis-CI will then deploy the new tag on Bintray
mvn release:clean
mvn release:prepare -Darguments="-DskipTests" -DpushChanges=false
git push --follow-tagsIf something weird happen, just rollback
mvn release:rollback
mvn release:cleanTravis-CI: https://travis-ci.org/Treydone/mandrel/
Architecture
Overview
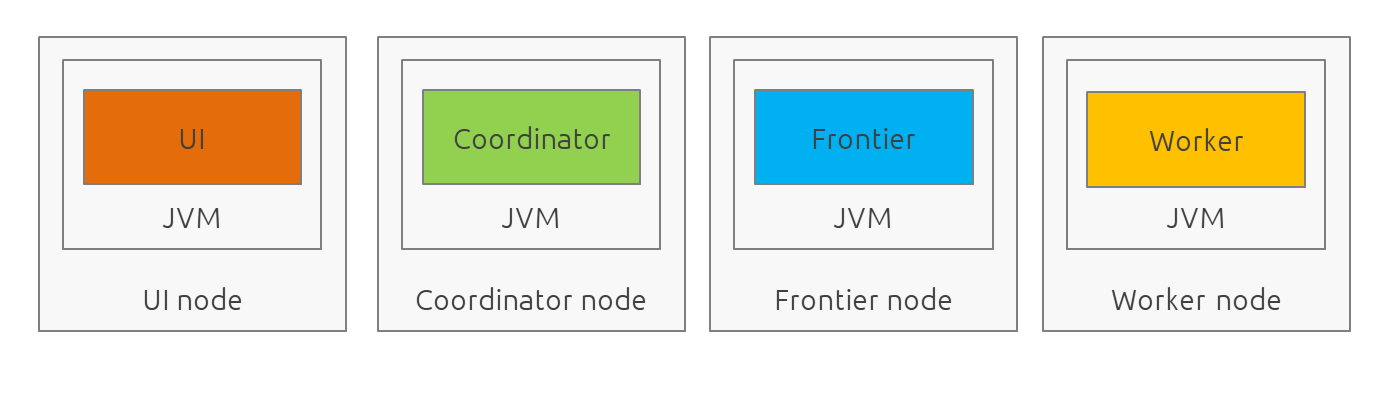
Mandrel is designed as a distributed system with dedicated/specialized components. In contrast to some projects or architecture like Mercator, Mandrel is composed by 4 types of instances: a UI, a coordinator, a frontier and a worker.
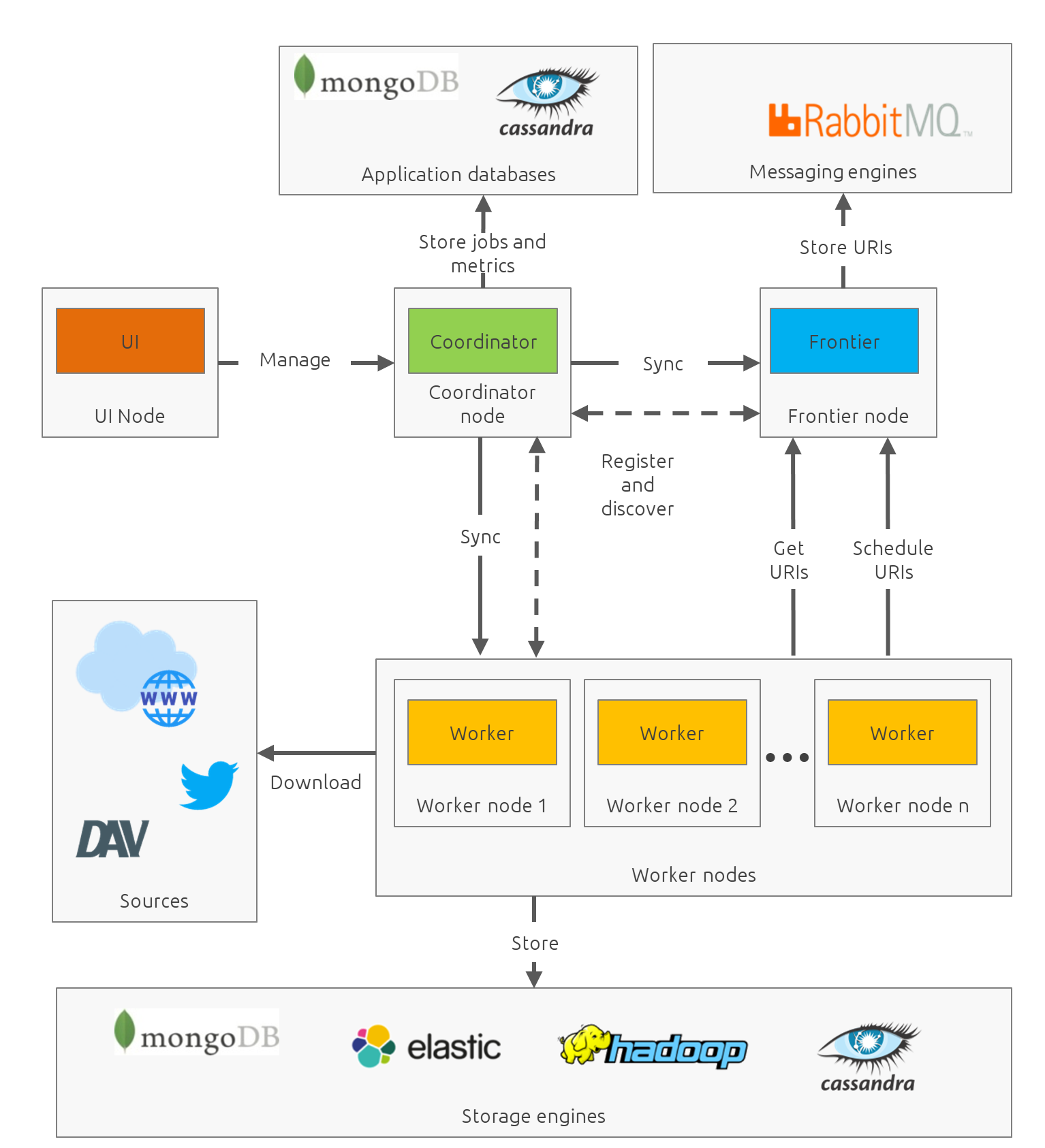
Components
UI
The UI is just a web frontend for presenting the data for the users and allowing the users to manage the jobs.
Coordinator
The coordinator is the main process in a Mandrel deployment and has several roles:
-
managing the jobs deployment on the workers and on the frontiers
-
collecting metrics
-
exposing the REST endpoints
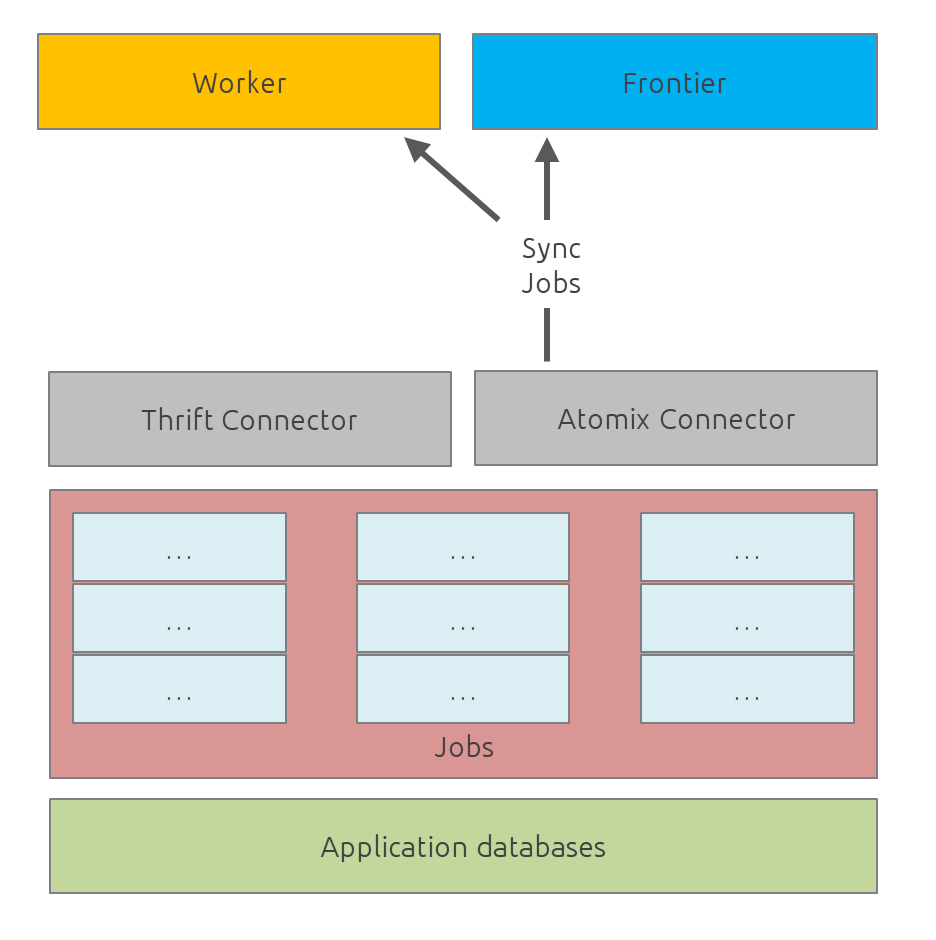
Worker
The goal of the worker is simple, it download and parse the content of uri given by the frontiers. Its workflow is more or less the following:
-
Pick out a uri from the frontier
-
Fetch the content
-
Store raw results in blobstore
-
Find links in the content
-
Store metadata in metadatastore
-
If extraction needed, parse the content and store the results in documentstore
A worker consists of:
-
fetchers: the fetchers dowload the remote content designated by a URI. There is one fetcher by protocol. By default there are three fetchers started in each worker: one for http/https, an other for ftp/ftps and a last for file.
-
chains: each active jobs results in a chain of processors
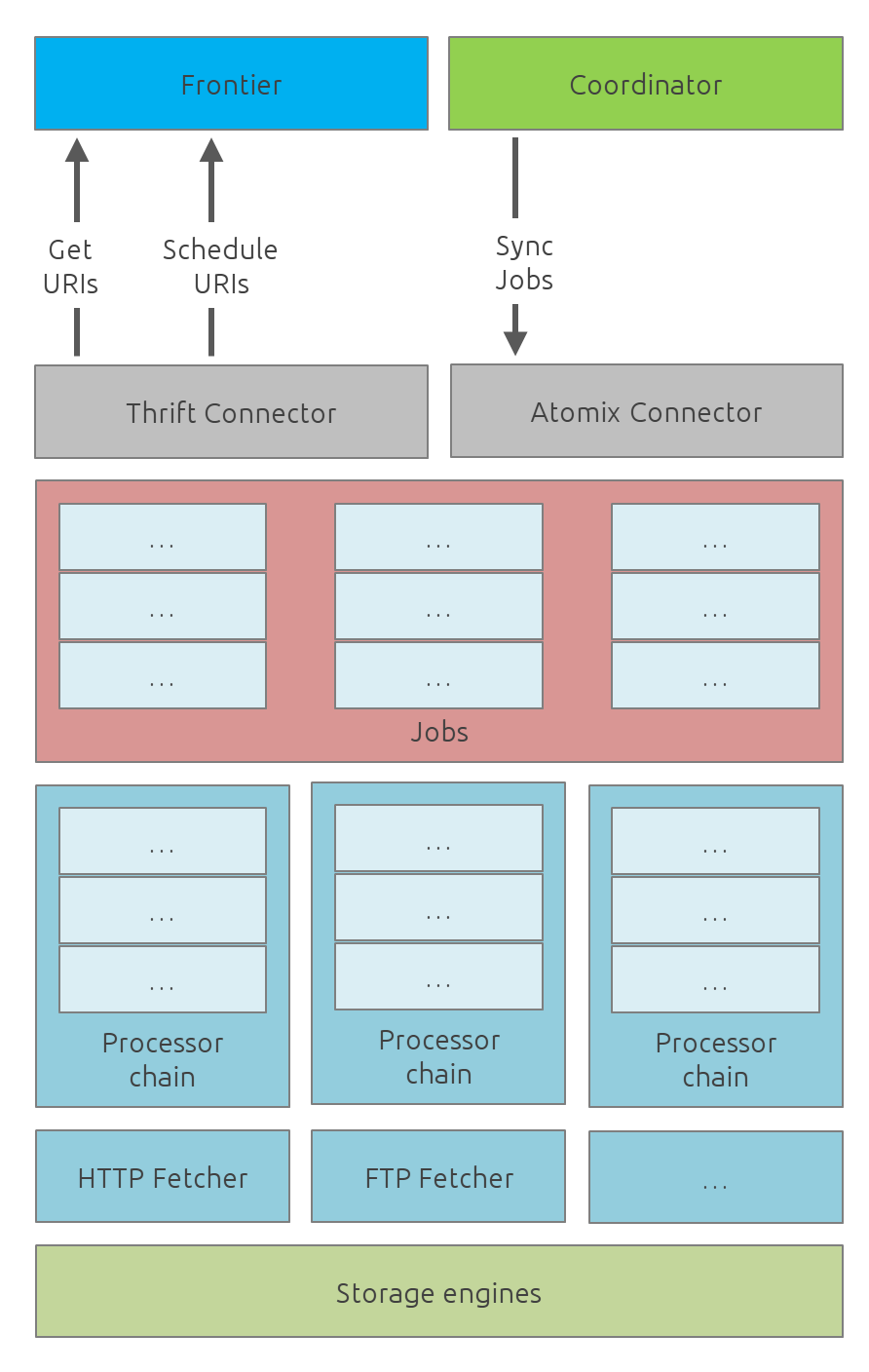
Processors
Processors are components that affect the mining.
Common processors:
-
link extraction by content-type
-
size-limiter/OOM prevent
For HTTP fetchers:
-
user-agent
-
headers
-
cookies
-
proxies
-
more…
For FTP fetchers:
-
proxies
-
more…
For HTML content-type responses: - HTML full interpretation
Frontier
The goal of the frontier is to know which URI to process next, and when. The frontier decides the logic and policies to follow when a crawler is visiting sources like websites: what pages should be crawled next, priorities and ordering, how often pages are revisited, etc. It keeps the state of the crawl. This includes, but is not limited to:
-
What URIs have been discovered
-
What URIs are being processed (fetched)
-
What URIs have been processed
The frontier garanties the respect of the politeness like the bandwidth limits or the number of pages to be crawled.
The frontier is set of various background tasks:
-
Priorizer: from a set of URIs, schedule the priority of the URIs and push them in the internal queues
-
Revisiter: revisit a page, when and how
Running modes
Standalone - Single-JVM
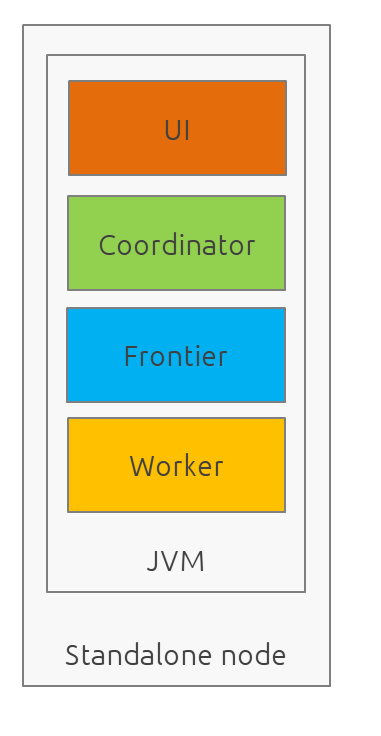
Start using:
$ ./bin/standaloned start
Stop using:
$ ./bin/standaloned stop
Distributed
$ ./bin/coordinatord start
$ ./bin/frontierd start
$ ./bin/workerd start
$ ./bin/ui-serverd start$ ./bin/workerd start
$ ./bin/frontierd start
$ ./bin/coordinatord stop
$ ./bin/ui-serverd stopConfiguration
Common
Discovery
By default, Mandrel uses Atomix for the all the clustering operations like discovery and partitions.
discovery:
instanceHost: localhost
atomix:
hosts:
- localhost:50000discovery.instanceHost-
Description
The address what will be registered in the discovery.
Defaultlocalhost
discovery.atomix.hosts-
Description
A YAML list of servers in the Coordinator ensemble. For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com". By default this is set to localhost for local mode of operation. For a fully-distributed setup, this should be set to a full list of Coordinator ensemble servers.
Defaultlocalhost:50000
Zookeeper
Mandrel can also use Zookeeper as the clustering layer. You need to disable the atomix configuration before:
discovery:
instanceHost: localhost
atomix:
enabled: false
zookeeper:
enabled: true
connectString: localhost:2181
root: /mandreldiscovery.zookeeper.connectString-
Description
Comma separated list of servers in the ZooKeeper ensemble. For example, "host1.mydomain.com,host2.mydomain.com,host3.mydomain.com". By default this is set to localhost for local and pseudo-distributed modes of operation. For a fully-distributed setup, this should be set to a full list of ZooKeeper ensemble servers.
Defaultlocalhost:2181
discovery.zookeeper.root-
Description
The root path in Zookeeper where the services will be registered. list of Coordinator ensemble servers.
Default/mandrel
Transport
transport:
bindAddress: localhost
port: 8090
local: falsediscovery.bindAddress-
Description
The address what will be used for binding.
Defaultlocalhost
discovery.port-
Description
The port what will be used for listening.
Default8090
discovery.local-
Description
Only for standalone mode. When in standalone, if the transport layer have to use the local transport which allows in VM communication.
Defaultfalse
Logging
logging:
console:
enabled: true
level: WARN
level:
org.springframework: INFO
io.mandrel: DEBUG
io.mandrel.messaging: DEBUGui.yml
server:
port: 8080
undertow:
buffer-size: 16000
buffers-per-region: 20
direct-buffers: true
io-threads: 4
worker-threads: 32server.port-
Description
The port used for all HTTP incoming traffic.
Default8080
coordinator.yml
server:
port: 8080
undertow:
buffer-size: 16000
buffers-per-region: 20
direct-buffers: true
io-threads: 4
worker-threads: 32server.port-
Description
The port used for all HTTP incoming traffic.
Default8080
frontier.yml
spring:
pidfile: frontier.pid
application:
name: frontier
admin:
enabled: false
jmx:
enabled: falseworker.yml
spring:
pidfile: worker.pid
application:
name: worker
admin:
enabled: false
jmx:
enabled: falsestandalone.yml
spring:
pidfile: standalone.pid
application:
name: standalone
admin:
enabled: false
data:
mongodb:
uri: mongodb://localhost:27017/mandrel
jmx:
enabled: falseScalabilty
All the components in Mandrel can have multiple instances:
-
Multiple coordinators for high-availibility on the main component in Mandrel deployment
-
Multiple frontiers in order to dsitribute the heavy job of priorization and reschedule
-
Multiple workers in order to grow up the bandwidth
All these instances are registered in the Coordinator ensemble.
Data mining
Content
Storage
Redundant Content
Shingling algorithm
Cloaked Content
Cloaking refers to the practice of serving different content to crawlers than to the real human viewers of a site. Cloaking is not in all cases malicious: many web sites with dynamic and/or interactive content rely on JavaScript.
Traps
Some websites install honeypots or traps to detect web crawlers. In case of a web crawler, a trap is a set of web pages that may intentionally or unintentionally be used to cause the web crawler to make an infinite number of requests or cause a poorly constructed crawler to crash. Traps may be created to "catch" spambots or other crawlers that waste a website’s bandwidth. They may also be created unintentionally by calendars that use dynamic pages with links that continually point to the next day or year. There is no algorithm to detect all traps, some classes of traps can be detected automatically, but new, unrecognized traps arise quickly.
Large link
Links with a huge size have to be skipped for preventing Mandrel to crash.
Hidden link
This trap usually consists of links that normal user can’t see but a bot can not. Mandrel takes care that the link has proper visibility:
-
no nofollow tag (html documents)
-
no CSS style display:none or color disguised to blend in with the page’s background color (html documents)
-
documents with session-id’s based on required cookies
Infinite deep
An other way to trap a crawler is to create an indefinitely deep directory structures like: http://foo.com/bar/foo/bar/foo/bar/foo/bar/…;..
In order to avoid this, Mandrel allows you to configure some properties in to order to configure:
-
the maximum number of directories to crawl from the root URL
-
the maximum number of sub directories Mandrel should crawl in a website
-
the maximum number of files in a directory
High links density
Dynamic pages that produce an unbounded number of documents to follow, for instance: calendars and algorithmically generated language poetry.
Infinite or large content size
Allows you to limit the size of the content to be fetched and avoid memory overhead during the content extraction.
Fetching
DNS resolution
DNS requests can take a long time due to the request-forwarding nature of the protocol. Therefore, Mandrel maintain its own DNS cache. Entries are expired according to both an eviction and expiration policies.
URIs
Extraction and canonicalization
path_clean-
Description
remove ‘..’ and its parent directory from the URL path. Therefore, URI path /%7Epage/sub1/sub2/../file.zip is reduced to /%7Epage/sub1/file.zip.
lowercase-
Description
convert the protocol and hostname to lowercase. For example, HTTP://www.DUMMY.com is converted to http://www.dummy.com.
strip_userinfo-
Description
strip any 'userinfo' found on http/https URLs.
strip_www-
Description
strip the first 'www.' found
strip_extra_slashes-
Description
strip any extra slashes, '/', found in the path. Use this rule to equate 'http://www.foo.org//A//B/index.html' and 'http://www.foo.org/A/B/index.html'."
strip_anchor-
Description
remove the ‘anchor’ or ‘reference’ part of the URI. Hence, http://dummy.com/faq.html#ancor is reduced to http://dummy.com/faq.html.
encode-
Description
perform URI encoding for some characters and preventing the crawler from treating http://dummy.com/~page/ as a different URI from http://dummy.com/~%7Epage/.
default_index_html-
Description
use heuristics to recognize default Web pages. File names such as index.html or index.htm may be removed from the URI with the assumption that they are the default files. If that is true, they would be retrieved by simply using the base URI.
default_port-
Description
add port 80 when no port number is specified for HTTP request.
strip_session_ids-
Description
strip known session ids like jessionid, CFID, CFTOKEN, PHPSESSID …
fixup_query-
Description
strip any trailing question mark
reorder_params-
Description
Reorder params
Exploration
-
Path-ascending crawling Mandrel is configured to download as many resources as possible and ascend to every path in each URI that it intends to fetch. For example, when the URI of http://dummy.com/a/b/page.html is found during extraction, Mandrel will attempt to crawl /a/b/, /a/, and /. Path-ascending crawlers are very effective in finding isolated resources, or resources for which no inbound link would have been found in regular crawling.
-
Focused/topical crawling Mandrel can also be intended to download sources that are similar to each other.
Revisit policies
-
Freshness: This is a binary measure that indicates whether the local copy is accurate or not.
-
Age: This is a measure that indicates how outdated the local copy is.
-
Uniform policy: This involves re-visiting all pages in the collection with the same frequency, regardless of their rates of change.
-
Proportional policy: This involves re-visiting more often the pages that change more frequently. The visiting frequency is directly proportional to the (estimated) change frequency.
Politeness
Good citizens
Mandrel is a “good citizens” as it will not impose too much traffic on the sources it will crawl. It includes safety mechanisms in order to avoid to inadvertently carry out a denial-of-service attack. Mandrel can be configured to obey various policies on:
-
Max parallel connections
-
Max pages per second
-
Max bytes per second (bandwidth)
User-agent spoofing
Since every HTTP request made from a client may contains a user-agent header, using the same user-agent multiple times leads to the detection of a bot. User agent spoofing is one of the available solution for this. Mandrel allows you to specify a static user-agent or a list of user agents and pick a random one for each request. Don’t cheat with user-agents, do not pretend to be the Google Bot: Googlebot/2.1 (http://www.google.com/bot.html)
Rotating IPs and Proxies
Blocked and banned miners
If any of the following symptoms appear on the sources that you are crawling/fetching, it is usually a sign of being blocked or banned.
-
CAPTCHA pages for HTTP fetchers
-
Frequent response with HTTP 404, 301 or 50x errors, also for HTTP fetchers
-
Unusual content delivery delay
-
Frequent appearance of status codes indication of blocking:
-
301 Moved Temporarily
-
401 Unauthorized
-
403 Forbidden
-
404 Not Found
-
408 Request Timeout
-
429 Too Many Requests
-
503 Service Unavailable
-
Using Mandrel
Web UI
The Web UI is the simpliest way for using Mandrel, it is available on each coordinator. By default the HTTP port is 8080.
API REST
All the documentation can be found on the Swagger endpoint at: //TODO
API Conventions
Endpoints
Jobs
- GET
/jobs -
Description
List all the jobs
- GET
/jobs/{id} -
Description
Return a job
- GET
/jobs/{id}/start -
Description
Start
- GET
/jobs/{id}/stop -
Description
Stop
Nodes
- GET
/nodes -
Description
List all the nodes
- GET
/nodes/{id} -
Description
Find a node by its id
Data
Cluster
Job definition
Introduction
A job is at least composed by:
-
sources: a set of sources (static list of uris, files, endpoint…) containing uris
-
stores: where to stores the raw data and their metadata
-
frontier: the list of uris discovered to be fetched or revisited
-
client: the bridge between Mandrel and the uris to be crawled, by default contains an HTTP/S and a FTP/S client
You can also define:
-
filters: if you want to fetch only a specific type of uri (on the same domain, only starting with a prefix…)
-
extractors: if your want to extract some data from the downloaded content
Examples
Let’s see some examples!
IMDB
Filtering
You can add filters to your job. There are two types of filters:
-
link filters
-
blob filters
Link filters apply conditions only on the link whereas blob filters apply conditions on the downloaded blob. This means also that link filters are applied BEFORE the crawling and blob filters AFTER. Take this in consideration when developping new jobs
Link filters
Domains
Example:
{
"type":"allowed_for_domains",
"domains": [
"mydomain1",
"mydomain2"
]
}Skip ancor
Example:
{
"type":"skip_ancor"
}Pattern
Example:
{
"type":"pattern",
"pattern": "..."
}Sanitize
Remove all the parameters in a URI (tck=…, timestamp=…, adsclick=…)
Example:
{
"type":"sanitize_params"
}Booleans
or|and|not|true|false
Example:
{
"not": {
"type":"allowed_for_domains",
"domains": [
"mydomain1",
"mydomain2"
]
}
}{
"and": [
{
"type":"allowed_for_domains",
"domains": [
"mydomain1",
"mydomain2"
]
},
{
"type":"pattern",
"pattern": "..."
}
]
}To be continued…
-
Keep only some parameters
-
…
Blob filters
Size
Booleans
or|and|not|true|false
To be continued…
Raw exporting
Your job is now done. Or not. We don’t care, we just want to export the raw data of the pages/documents. You have to two ways to do this:
-
Extract the data from the page store if you have specified one during the creation (SQL, Cassandra…)
-
Use the dedicated endpoint
$ curl -X GET http://localhost:8080/jobs/wikipedia/raw/export?format=csv|jsonTo be continued…
-
Define options for the exporters
-
Add formats for parquet
-
Support compression
Frontier
Extracting
Somethimes we want to crawl pages. But what we really want is the data INSIDE the pages.
$ curl -X POST http://localhost:8080/jobs/imdb -d '
{
"sources":[
{
"type":"fixed",
"urls":[
"http://www.imdb.com/"
]
}
],
"extractors":[
{
"name":"movie_extractor"
"filters":[
{
"type":"patterns",
"value":[
"/title"
]
}
],
"fields":[
{
"title":{
"extractor":{
"type":"xpath",
"value":"//*[@id="overview-top"]/h1/span[1]/text()",
"source":"body"
}
}
},
{
"description":{
"extractor":{
"type":"xpath",
"value":"//*[@id="overview-top"]/p[2]/text()",
"source":"body"
}
}
},
{
"actors":{
"extractor":{
"type":"xpath",
"value":"//*[@id="overview-top"]/div[6]/a/span",
"source":"body"
}
}
}
]
}
]
}
'This will extract the fields 'title', 'description' and 'actors' from the page.
Data exporting
Ok, now we got some data, we can export them by calling:
$ curl -X POST http://localhost:8080/jobs/export/movie_extractor?format=csv|jsonJSON
{
"type":"json"
}Delimited separated values
{
"type":"csv",
"quote_char":"\"",
"delimiter_values":44,
"delimiter_multivalues":124,
"keep_only_first_value":false,
"add_header":true,
"end_of_line_symbols":"\r\n"
}Blob & metadata stores
Example for using Mongo:
{
"stores":{
"metadata":{
"type":"mongo"
},
"blob":{
"type":"mongo"
}
}
}The store for blob is not mandatory, if you extract data via extractors for instance, but the metadata is:
{
"stores":{
"metadata":{
"type":"mongo"
},
"blob":null
}
}Mongo
Blob, metadata, document
"stores" : {
"metadata" : {
"type" : "mongo",
"uri" : "mongodb://localhost",
"database" : "mandrel",
"collection" : "metadata_{0}",
"batch_size" : 1000
},
"blob" : {
"type" : "mongo",
"uri" : "mongodb://localhost",
"database" : "mandrel",
"bucket" : "blob_{0}",
"batch_size" : 10
}
}Document stores
Mongo
"extractors" : {
"data" : [
{
"store" : {
"type" : "mongo",
"uri" : "mongodb://localhost",
"database" : "mandrel",
"collection" : "document_{0}",
"batch_size" : 1000
}
}
]
}Elasticsearch
Document
"extractors" : {
"data" : [
{
"store" : {
"type" : "elasticsearch",
"addresses" : ["localhost:9300"],
"type" : "document",
"index" : "mandrel_{0}",
"cluster" : "mandrel",
"batch_size" : 1000
}
}
]
}Redis
Mutliple output
Client
Each job can be configured with a specified client in order to configure:
-
Proxies
-
Request and connection timeouts
-
User-agent generation
-
Custom cookies (jsessionid…) and headers (X-Request-By, Basic-Authentication…)
-
DNS resolution strategies …
{
"request_time_out":3000,
"headers":null,
"params":null,
"follow_redirects":false,
"cookies":null,
"user_agent_provisionner":{
"type":"fixed",
"ua":"Mandrel"
},
"dns_cache":{
"type":"internal"
},
"proxy":{
"type":"no"
},
"politeness":{
"global_rate":1000,
"per_node_rate":500,
"max_pages":500,
"wait":100,
"ignore_robots_txt":false,
"recrawl_after":-1
}
}Production considerations & performance tuning
|
Note
|
Section pending |
By default, Mandrel is started in a standalone mode. In this mode, the 3 main components are started in the same JVM. Altought this may be useful for testing purposes, the standalone mode does not allow you to scale your deployment.
For production, we recommand you to deploy at least one coordinator, one frontier and one worker, each in separate JVM on a dedicated serveur.
High Availability
The Coordinator is the main component and can be multi-instanced. For solid production deployment, use 3 or 5 coordinators. The coordinator is a low resource component, you can colocate a coordinator with a worker or a frontier, but you should not share the same server for a worker AND a frontier.
General Guidelines
Avoid small machines, because you don’t want to manage a cluster with a thousand nodes, and the overhead of simply running Mandrel is more apparent on such small boxes, prefer medium-sized machines.
Firewall
Unless using one or more known and/or internal proxies for downloading the content from the workers, avoid placing firewall rules between the components consistuing a Mandrel deployment. However, if you don’t have the choice, here are the interactions between the components (assuming the default transport and configuration):
-
user → UI-server on TCP for HTTP:8080 or HTTPS:8443
-
UI-server → coordinators on TCP:8090
-
worker → frontier on TCP:8092
-
coordinator → worker on TCP:8091
-
coordinator → frontier on TCP:8092
-
worker → engine storage (?)
-
frontier → messenging storage (?)
-
coordinator → application database (?)
Operating System
64-bit
Use a 64-bit platform (and 64-bit JVM too).
Swapping
Watch out for swapping. Set swappiness to 0.
Ulimit
Most UNIX-like operating systems, including Linux and OS X, provide ways to limit and control the usage of system resources such as threads, files, and network connections on a per-process and per-user basis. These “ulimits” prevent single users from using too many system resources. Sometimes these limits have too low default values that can cause a number of issues in the course of normal Mandrel operation.
You can use the ulimit command at the system prompt to check system limits, as in the following example:
$ ulimit -a
-t: cpu time (seconds) unlimited
-f: file size (blocks) unlimited
-d: data seg size (kbytes) unlimited
-s: stack size (kbytes) 8192
-c: core file size (blocks) 0
-m: resident set size (kbytes) unlimited
-u: processes 31423
-n: file descriptors 65536
-l: locked-in-memory size (kbytes) 64
-v: address space (kbytes) unlimited
-x: file locks unlimited
-i: pending signals 31423
-q: bytes in POSIX msg queues 819200
-e: max nice 0
-r: max rt priority 0
-N 15: unlimitedRecommended ulimit settings
Every deployment may have unique requirements and settings; however, the following thresholds and settings are particularly important for Mandrel deployments:
-f (file size): unlimited
-t (cpu time): unlimited
-v (virtual memory): unlimited
-n (open files): 64000
-m (memory size): unlimited
-u (processes/threads): 64000Network
A fast and reliable network is obviously important to performance in a distributed system. Low latency helps ensure that nodes can communicate easily, while high bandwidth helps shard movement and recovery. Modern data-center networking (1 GbE, 10 GbE) is sufficient for the vast majority of clusters.
In case of a huge web data miner, if possible, prefer machines with two network cards: one for the internal communication (Mandrel and the engine/messaging storages) and an other for the Internet access.
Java
Cloud
Be aware of the cost introduced by fetching too much data…
Case studies
Troubleshooting
|
Note
|
Section pending |
Glossary
|
Note
|
Section pending |
- coordinator
-
is the main process for a Mandrel infrastructure.
- frontier
-
is the process keeping the state of the jobs.
- standalone
-
a all-in-one process composed by the ui, worker, frontier and coordinator
- worker
-
is the process collecting the data from the source.
Appendix A: Bibliography
Appendix B: Copyright and License
|
Note
|
Section pending |
This software is licensed under the Apache License, version 2 ("ALv2"), quoted below.
Copyright 2009-2016 Mandrel
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.